Import workflow from template
Build workflow from a template
The precisely same workflow can be created by importing
the steps from a template file. In SPR, we use R Markdown files as templates. As
demonstrated above, it is required to initialize the project with SPRproject
function.
suppressPackageStartupMessages({
library(systemPipeR)
})
importWF
importWF function will scan and import all the R chunk from the R Markdown
file and build all the workflow instances. Then, each R chuck in the file will
be converted in a workflow step.
We have prepared the template for you already. Let’s first see what is in the template or can be read here:
cat(readLines(system.file("extdata", "spr_simple_wf.Rmd", package = "systemPipeR")), sep = "\n")
---
title: "Simple Workflow by systemPipeR"
author: "Author: Daniela Cassol, Le Zhang, and Thomas Girke"
date: "Last update: `r format(Sys.time(), '%d %B, %Y')`"
output:
BiocStyle::html_document:
toc_float: true
code_folding: show
package: systemPipeR
vignette: |
%\VignetteEncoding{UTF-8}
%\VignetteIndexEntry{Workflow example}
%\VignetteEngine{knitr::rmarkdown}
fontsize: 14pt
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
```
# Build the Workflow
- Load `systemPipeR` library:
```{r load_library, eval=TRUE, spr=TRUE}
appendStep(sal) <- LineWise(code={
library(systemPipeR)
},
step_name = "load_library",
dependency = NA)
```
## Export dataset to file
- Add first step as `LineWise`
```{r export_iris, eval=TRUE, spr=TRUE}
appendStep(sal) <- LineWise(code={
mapply(
function(x, y) write.csv(x, y),
split(iris, factor(iris$Species)),
file.path("results", paste0(names(split(iris, factor(iris$Species))), ".csv")))
},
step_name = "export_iris",
dependency = "load_library")
```
## Compress data
- Adding the second step, as `SYSargs2`
```{r gzip, eval=TRUE, spr=TRUE, spr.dep=TRUE}
targetspath <- system.file("extdata/cwl/gunzip", "targets_gunzip.txt", package = "systemPipeR")
appendStep(sal) <- SYSargsList(step_name = "gzip",
targets = targetspath, dir = TRUE,
wf_file = "gunzip/workflow_gzip.cwl", input_file = "gunzip/gzip.yml",
dir_path = system.file("extdata/cwl", package = "systemPipeR"),
inputvars = c(FileName = "_FILE_PATH_", SampleName = "_SampleName_"),
dependency = "export_iris")
```
## Decompress data
```{r gunzip, eval=TRUE, spr=TRUE}
appendStep(sal) <- SYSargsList(step_name = "gunzip",
targets = "gzip", dir = TRUE,
wf_file = "gunzip/workflow_gunzip.cwl", input_file = "gunzip/gunzip.yml",
dir_path = system.file("extdata/cwl", package = "systemPipeR"),
inputvars = c(gzip_file = "_FILE_PATH_", SampleName = "_SampleName_"),
rm_targets_col = "FileName",
dependency = "gzip")
```
## Import data to R and perform statistical analysis and visualization
```{r stats, eval=TRUE, spr=TRUE}
appendStep(sal) <- LineWise(code={
df <- lapply(getColumn(sal, step="gunzip", 'outfiles'), function(x) read.delim(x, sep=",")[-1])
df <- do.call(rbind, df)
stats <- data.frame(cbind(mean=apply(df[,1:4], 2, mean),
sd=apply(df[,1:4], 2, sd)))
stats$species <- rownames(stats)
plot <- ggplot2::ggplot(stats, ggplot2::aes(x=species, y=mean, fill=species)) +
ggplot2::geom_bar(stat = "identity", color="black", position=ggplot2::position_dodge()) +
ggplot2::geom_errorbar(ggplot2::aes(ymin=mean-sd, ymax=mean+sd), width=.2,
position=ggplot2::position_dodge(.9))
},
step_name = "stats",
dependency = "gunzip",
run_step = "optional")
```
SPR chunks
The SPR templates has no difference than a normal R markdown file, except one little thing – the SPR chunks.
To make a normal R chunk also a SPR chunk, in the chunk header spr=TRUE or
spr=T option needs to be appended.
For example:
```{r step_1, eval=TRUE, spr=TRUE}
```{r step_2, eval=FALSE, spr=TRUE}
Note here the eval=FALSE, by default steps with this option will still
be imported, but you can use ignore_eval flag to change it in importWF.
Preprocess code
Inside SPR chunks, before the actual step definition, there is some special space called preprocess code.
Why do need preprocess code? When we import/create the workflow steps, these
steps are not really executed when the time of creation, no matter it is a sysArgs
step or a Linewise step. However, in many cases, we need to connect different previous steps'
outputs to the inputs of the next. This is easy to handle between sysArgs steps via the targets
argument connection. If it is a Linewise step to a sysArgs step. Things become
tricky. Since Linewise code is not run at the time of step definition, no
output paths are generated, so the next sysArgs step cannot find the inputs.
To overcome this problem, preprocess code feature is introduced. Defining preprocess
code is very easy. Write any lines of R code below the SPR chunk header line. Right
before the step is defined, insert one line of comment of ###pre-end to indicate
the completion of preprocess code. For example:
targetspath <- system.file("extdata", "cwl", "example", "targets_example.txt", package = "systemPipeR")
###pre-end
appendStep(sal) <- SYSargsList(
step_name = "Example",
targets = targetspath,
wf_file = "example/example.cwl", input_file = "example/example.yml",
dir_path = system.file("extdata/cwl", package = "systemPipeR"),
inputvars = c(Message = "_STRING_", SampleName = "_SAMPLE_")
)
In the example above the targets path is not directly loaded but given through an intermediate
variable targetspath. This is a simple example, other useful actions like path
concatenation, checking file integrity before piping to expensive (slow) functions
can also be done in preprocess. Another good example will be the
ChIPseq workflow.
Watch closely how the output of LineWise step merge_bams is predicted and writing to an intermediate targets file
on-the-fly in the preprocess code of
call_peaks_macs_withref
so it can be used in the call_peaks_macs_withref step creation as input targets.
Actually, if the SPR chunk has R code before the step definition but ###pre-end
delimiter is not added, these code will still be evaluated at the time of import.
However, these lines of code will not be store in the SYSargsList, so later
when you render the report (renderReport) or export the workflow as a new template
(sal2rmd), these lines will not be included. That means, these lines are
one-shot reprocess code and not reproducible.
Other rules
-
For SPR chunks, the last object assigned must to be the
SYSargsList, for example asysArgs2(commandline) steps:targetspath <- system.file("extdata/cwl/example/targets_example.txt", package = "systemPipeR") appendStep(sal) <- SYSargsList(step_name = "Example", targets = targetspath, wf_file = "example/example.cwl", input_file = "example/example.yml", dir_path = system.file("extdata/cwl", package = "systemPipeR"), inputvars = c(Message = "_STRING_", SampleName = "_SAMPLE_"))OR a
Linewise(R) step:appendStep(sal) <- LineWise(code = { library(systemPipeR) }, step_name = "load_lib") -
Also, note that all the required files or objects to generate one particular step must be defined in an imported R code. The motivation for this is that when R Markdown files are imported, the
spr = TRUEflag will be evaluated, append, and stored in the workflow control class as theSYSargsListobject. -
The workflow object name used in the R Markdown (e.g.
appendStep(sal)) needs to be the same when theimportWFfunction is used. Usually we use the namesal( short abbreviation forsysargslist). It is important to keep consistency. If different object names are used, when running the workflow, you can see a error, like Error:object not found.. -
Special in
importWF: SPR chunk names will be used as step names, and it has higher priority than thestepnameargument. For example, the chunk header is{r step_1, eval=TRUE, spr=TRUE}, and the insideSYSargsListoption isSYSargsList(step_name = "step_99", ...). After the import, step name will be overwritten to"step_1"instead of"step_99".
start to import
sal_rmd <- SPRproject(logs.dir = ".SPRproject_rmd")
## Creating directory: /home/lab/Desktop/spr/systemPipeR.github.io/content/en/sp/spr/sp_run/data
## Creating directory: /home/lab/Desktop/spr/systemPipeR.github.io/content/en/sp/spr/sp_run/param
## Creating directory: /home/lab/Desktop/spr/systemPipeR.github.io/content/en/sp/spr/sp_run/results
## Creating directory '/home/lab/Desktop/spr/systemPipeR.github.io/content/en/sp/spr/sp_run/.SPRproject_rmd'
## Creating file '/home/lab/Desktop/spr/systemPipeR.github.io/content/en/sp/spr/sp_run/.SPRproject_rmd/SYSargsList.yml'
sal_rmd <- importWF(sal_rmd, file_path = system.file("extdata", "spr_simple_wf.Rmd", package = "systemPipeR"))
## Reading Rmd file
##
## ---- Actions ----
## Checking chunk eval values
## Checking chunk SPR option
## Ignore non-SPR chunks: 17
## Parse chunk code
## Checking preprocess code for each step
## No preprocessing code for SPR steps found
## Now importing step 'load_library'
## Now importing step 'export_iris'
## Now importing step 'gzip'
## Now importing step 'gunzip'
## Now importing step 'stats'
## Now back up current Rmd file as template for `renderReport`
## Template for renderReport is stored at
## /home/lab/Desktop/spr/systemPipeR.github.io/content/en/sp/spr/sp_run/.SPRproject_rmd/workflow_template.Rmd
## Edit this file manually is not recommended
## import done
sal_rmd
## Instance of 'SYSargsList':
## WF Steps:
## 1. load_library --> Status: Pending
## 2. export_iris --> Status: Pending
## 3. gzip --> Status: Pending
## Total Files: 3 | Existing: 0 | Missing: 3
## 3.1. gzip
## cmdlist: 3 | Pending: 3
## 4. gunzip --> Status: Pending
## Total Files: 3 | Existing: 0 | Missing: 3
## 4.1. gunzip
## cmdlist: 3 | Pending: 3
## 5. stats --> Status: Pending
##
We can see 5 steps are appended to our sal object.
Simple exploration
After import, we can explore the workflow to check the steps:
# list individual steps
stepsWF(sal_rmd)
## $load_library
## Instance of 'LineWise'
## Code Chunk length: 1
##
## $export_iris
## Instance of 'LineWise'
## Code Chunk length: 1
##
## $gzip
## Instance of 'SYSargs2':
## Slot names/accessors:
## targets: 3 (SE...VI), targetsheader: 1 (lines)
## modules: 0
## wf: 1, clt: 1, yamlinput: 4 (inputs)
## input: 3, output: 3
## cmdlist: 3
## Sub Steps:
## 1. gzip (rendered: TRUE)
##
##
##
## $gunzip
## Instance of 'SYSargs2':
## Slot names/accessors:
## targets: 3 (SE...VI), targetsheader: 1 (lines)
## modules: 0
## wf: 1, clt: 1, yamlinput: 4 (inputs)
## input: 3, output: 3
## cmdlist: 3
## Sub Steps:
## 1. gunzip (rendered: TRUE)
##
##
##
## $stats
## Instance of 'LineWise'
## Code Chunk length: 5
# list step dependency
dependency(sal_rmd)
## $load_library
## [1] NA
##
## $export_iris
## [1] "load_library"
##
## $gzip
## [1] "export_iris"
##
## $gunzip
## [1] "gzip"
##
## $stats
## [1] "gunzip"
# list R step code
codeLine(sal_rmd)
## gzip AND gunzip step have been dropped because it is not a LineWise object.
## load_library
## library(systemPipeR)
## export_iris
## mapply(function(x, y) write.csv(x, y), split(iris, factor(iris$Species)), file.path("results", paste0(names(split(iris, factor(iris$Species))), ".csv")))
## stats
## df <- lapply(getColumn(sal, step = "gunzip", "outfiles"), function(x) read.delim(x, sep = ",")[-1])
## df <- do.call(rbind, df)
## stats <- data.frame(cbind(mean = apply(df[, 1:4], 2, mean), sd = apply(df[, 1:4], 2, sd)))
## stats$species <- rownames(stats)
## plot <- ggplot2::ggplot(stats, ggplot2::aes(x = species, y = mean, fill = species)) + ggplot2::geom_bar(stat = "identity", color = "black", position = ggplot2::position_dodge()) + ggplot2::geom_errorbar(ggplot2::aes(ymin = mean - sd, ymax = mean + sd), width = 0.2, position = ggplot2::position_dodge(0.9))
# list step targets
targetsWF(sal_rmd)
## $load_library
## DataFrame with 0 rows and 0 columns
##
## $export_iris
## DataFrame with 0 rows and 0 columns
##
## $gzip
## DataFrame with 3 rows and 2 columns
## FileName SampleName
## <character> <character>
## SE results/setosa.csv SE
## VE results/versicolor.csv VE
## VI results/virginica.csv VI
##
## $gunzip
## DataFrame with 3 rows and 2 columns
## gzip_file SampleName
## <character> <character>
## SE results/SE.csv.gz SE
## VE results/VE.csv.gz VE
## VI results/VI.csv.gz VI
##
## $stats
## DataFrame with 0 rows and 0 columns
Update workflow
Maybe you have noticed some lines in the importing
Template for renderReport is stored at
xxxx/.SPRproject_rmd/workflow_template.Rmd
Edit this file manually is not recommended
It means current import is successful and a copy of your workflow template is
copied to this position, and it will be used for renderReport as the skeleton.
In real data analysis, the workflow template does not always stays the same, e.g. adding some
text, new steps to the template. One way we could add new steps is the interactive method.
The problem is this way does not contain any text description in the final report.
renderReport has a smart way to insert these new steps that do not exist in the
template to the right order but it cannot create text descrption for you.
Another way to import new steps or update text in the template is to use
importWF(..., update = TRUE).
Example 1
Let’s add a step and some text to
spr_simple_wf.Rmd
and try to update.
update = TRUEis highly interactive. It uses a Q&A style to ask users things like whether to update preprocess code of certain steps, whether to import certain new steps. In this mode, you can always say “no” to the choice, so you can choose to partially update the template.- Rendering the webpage document is not interactive, so here we use
importWF(..., update = TRUE, confirm = TRUE), which means confirm all the choices, say “yes” to all. Then, partially update is no longer the option here.
For the updated template, you can download here
One step, preprocess code and some description has been added to the end:
## A new step
This is a new step with some simple code to demonstrate the update of `importWF`
```{r session_info, eval=TRUE, spr=TRUE}
cat("some fake preprocess code\n")
###pre-end
appendStep(sal) <- LineWise(code={
sessionInfo()
},
step_name = "sessionInfo",
dependency = "stats")
```
# the file is with `.md` extension, but `importWF` needs `.Rmd`.
# we need to first download and change extension
tmp_file <- tempfile(fileext = ".rmd")
download.file(
"https://raw.githubusercontent.com/systemPipeR/systemPipeR.github.io/main/static/en/sp/spr/sp_run/spr_simple_wf_new.md",
tmp_file
)
sal_rmd <- importWF(sal_rmd, file_path = tmp_file, update = TRUE, confirm = TRUE)
## Reading Rmd file
##
## ---- Actions ----
## Checking chunk eval values
## Checking chunk SPR option
## Ignore non-SPR chunks: 17
## Parse chunk code
## Checking preprocess code for each step
## Update starts. Note for existing steps, update only fix the line number records. They are NOT imported again. If you have changed arguments in methods like `SYSargsList`, `Linewise`, `appendStep` in template for some steps, delete the original step from the workflow and rerun this function or manually to import it again, or use replacement methods to change arguments in current workflow, see ?`SYSargsList-class` help file. Otherwise, package would use what is in the current workflow to `renderReport` and `sal2rmd`. New arguments in the template will be ignored.
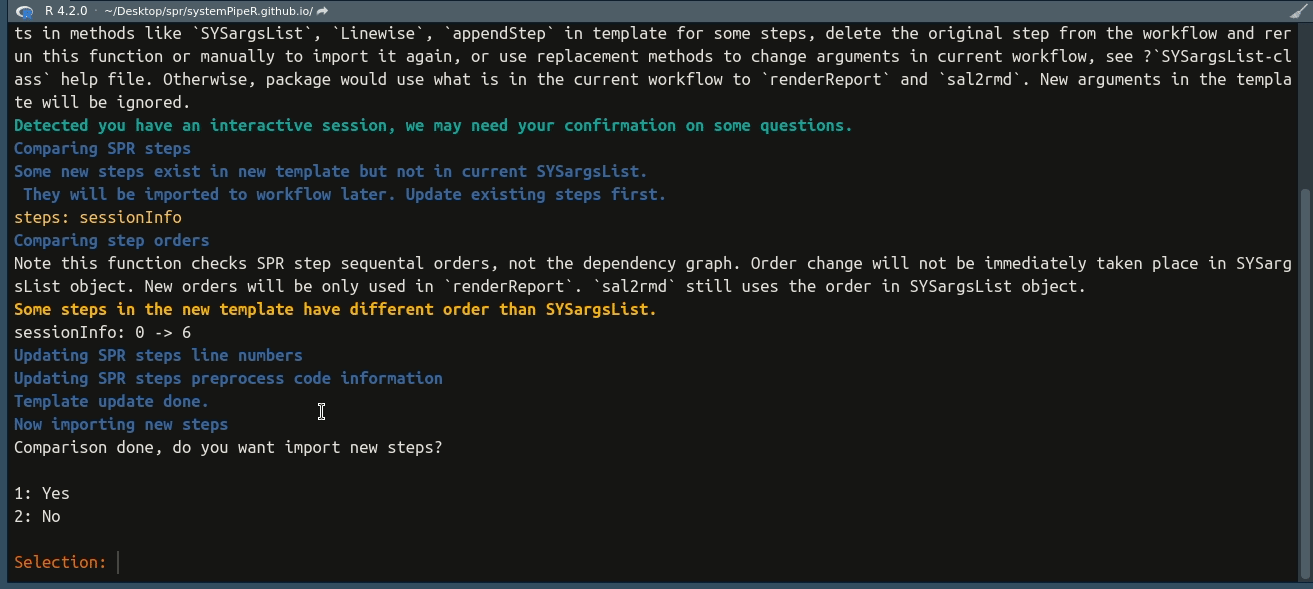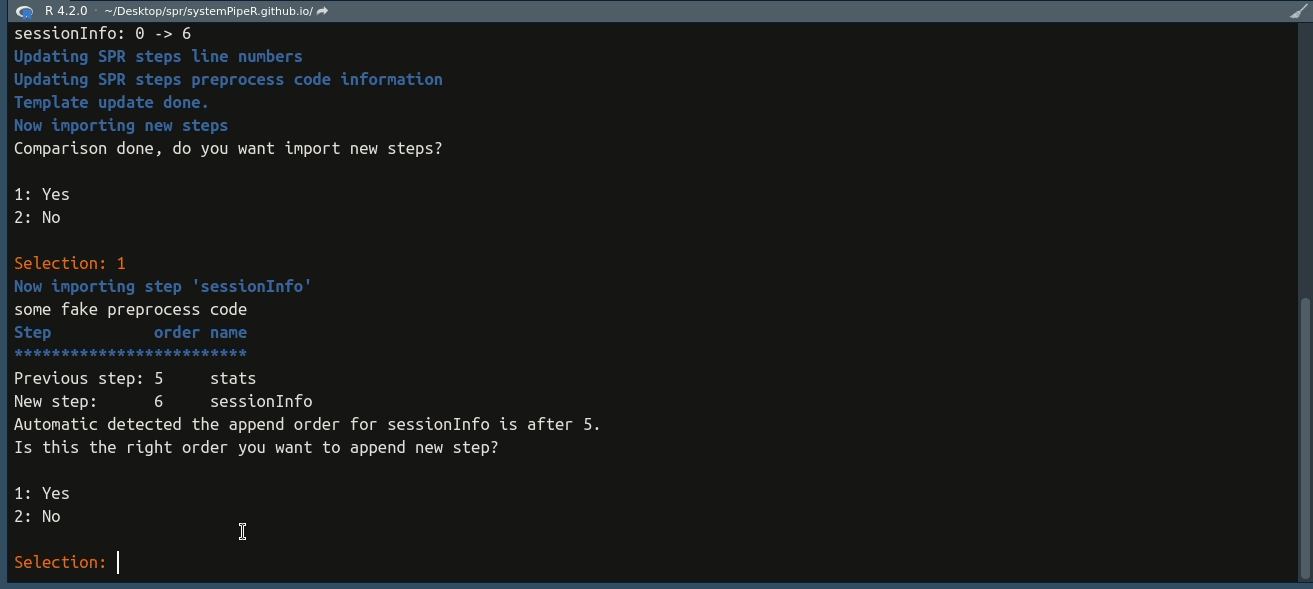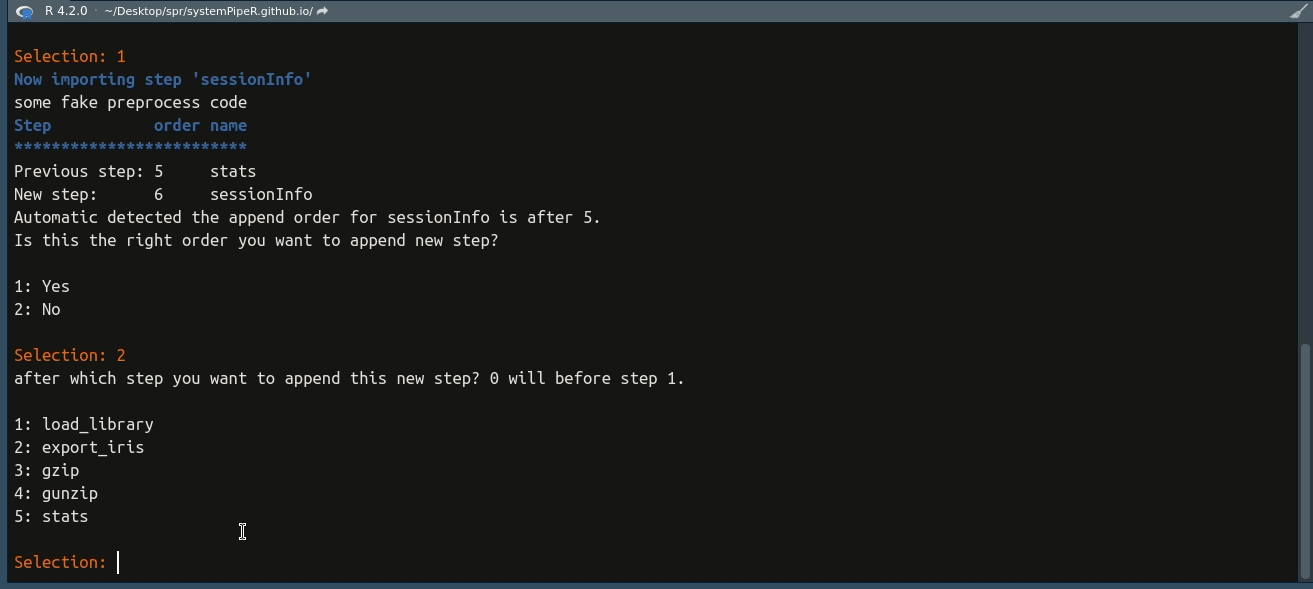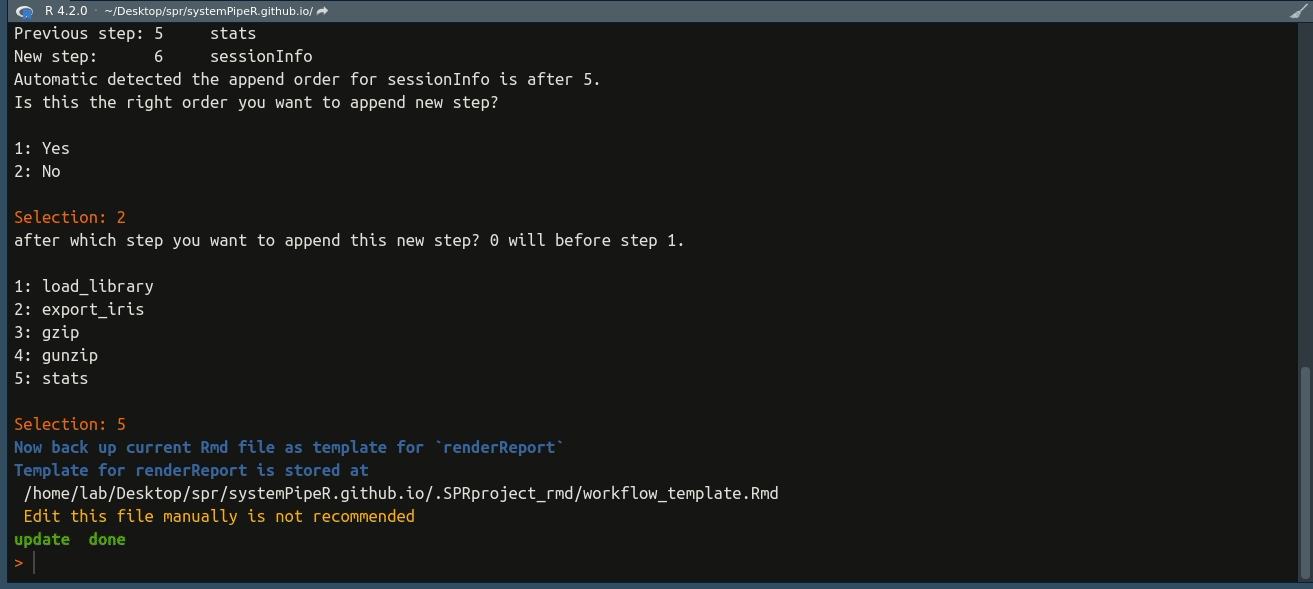
## Comparing SPR steps
## Some new steps exist in new template but not in current SYSargsList.
## They will be imported to workflow later. Update existing steps first.
## steps: sessionInfo
## Comparing step orders
## Note this function checks SPR step sequental orders, not the dependency graph. Order change will not be immediately taken place in SYSargsList object. New orders will be only used in `renderReport`. `sal2rmd` still uses the order in SYSargsList object.
## Some steps in the new template have different order than SYSargsList.
## sessionInfo: 0 -> 6
## Updating SPR steps line numbers
## Updating SPR steps preprocess code information
## Template update done.
## Now importing new steps
## Now importing step 'sessionInfo'
## some fake preprocess code
## Now back up current Rmd file as template for `renderReport`
## Template for renderReport is stored at
## /home/lab/Desktop/spr/systemPipeR.github.io/content/en/sp/spr/sp_run/.SPRproject_rmd/workflow_template.Rmd
## Edit this file manually is not recommended
## update done
We can see under update mode, importWF compare the old template and the new
template and find the difference. List all differences to users. It includes:
- List all new steps
- Compare step orders, update if needed
- update line number records of steps from old template to new template.
- update preprocess code
- finally import new steps
A new step has been successfully imported from the new template.
sal_rmd
## Instance of 'SYSargsList':
## WF Steps:
## 1. load_library --> Status: Pending
## 2. export_iris --> Status: Pending
## 3. gzip --> Status: Pending
## Total Files: 3 | Existing: 0 | Missing: 3
## 3.1. gzip
## cmdlist: 3 | Pending: 3
## 4. gunzip --> Status: Pending
## Total Files: 3 | Existing: 0 | Missing: 3
## 4.1. gunzip
## cmdlist: 3 | Pending: 3
## 5. stats --> Status: Pending
## 6. sessionInfo --> Status: Pending
##
Under interactive mode, users would have a lot more options. For example, when
adding a new step, importWF has a back-tracking algorithm that
automatically detects the right order where this step should be appended. However,
things can go wrong and it does not work 100%. Under interactive mode, the
program first lists the previous step where this new step would be appended after,
and then users have the option to choose whether this is the correct step. If not,
a new prompt would pop up to let the users to manually choose the right order
to append the new step. See the gif below.
This does not mean you could append a step to any place. It also has to meet the dependency requirement. For example, this new step is depend on step 5 but you manually choose to append it after step 1. Then, the import would fail.
Example 2
Let’s see another example
how importWF update preprocess code and line numbers
tmp_file2 <- tempfile(fileext = ".rmd")
download.file(
"https://raw.githubusercontent.com/systemPipeR/systemPipeR.github.io/main/static/en/sp/spr/sp_run/spr_simple_wf_new_precode_changed.md",
tmp_file2
)
sal_rmd <- importWF(sal_rmd, file_path = tmp_file2, update = TRUE, confirm = TRUE)
## Reading Rmd file
##
## ---- Actions ----
## Checking chunk eval values
## Checking chunk SPR option
## Ignore non-SPR chunks: 17
## Parse chunk code
## Checking preprocess code for each step
## Update starts. Note for existing steps, update only fix the line number records. They are NOT imported again. If you have changed arguments in methods like `SYSargsList`, `Linewise`, `appendStep` in template for some steps, delete the original step from the workflow and rerun this function or manually to import it again, or use replacement methods to change arguments in current workflow, see ?`SYSargsList-class` help file. Otherwise, package would use what is in the current workflow to `renderReport` and `sal2rmd`. New arguments in the template will be ignored.
## Comparing SPR steps
## Comparing step orders
## Updating SPR steps line numbers
## Updating step lines of stats 76:92 -> 79:95
## Updating step lines of sessionInfo 96:104 -> 99:108
## Updating SPR steps preprocess code information
## For step sessionInfo old preprocess code:
## cat("some fake preprocess code\n")
## ###pre-end
## New preprocess code:
## 1+1
## cat("some fake preprocess code that has been changed!\n")
## ###pre-end
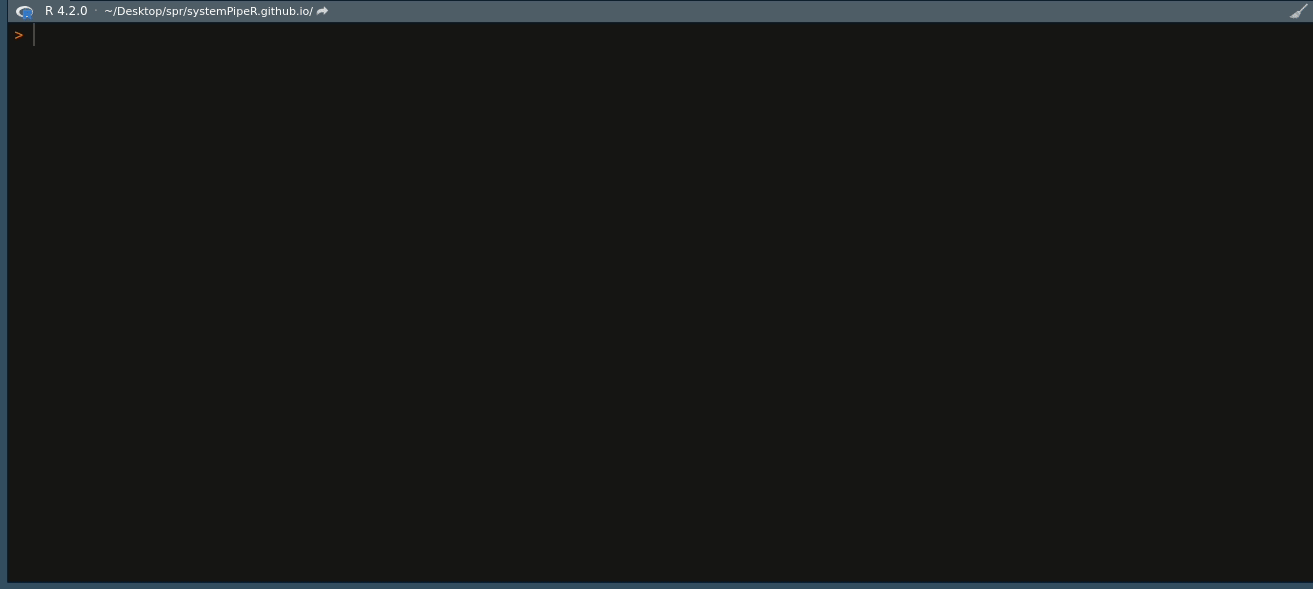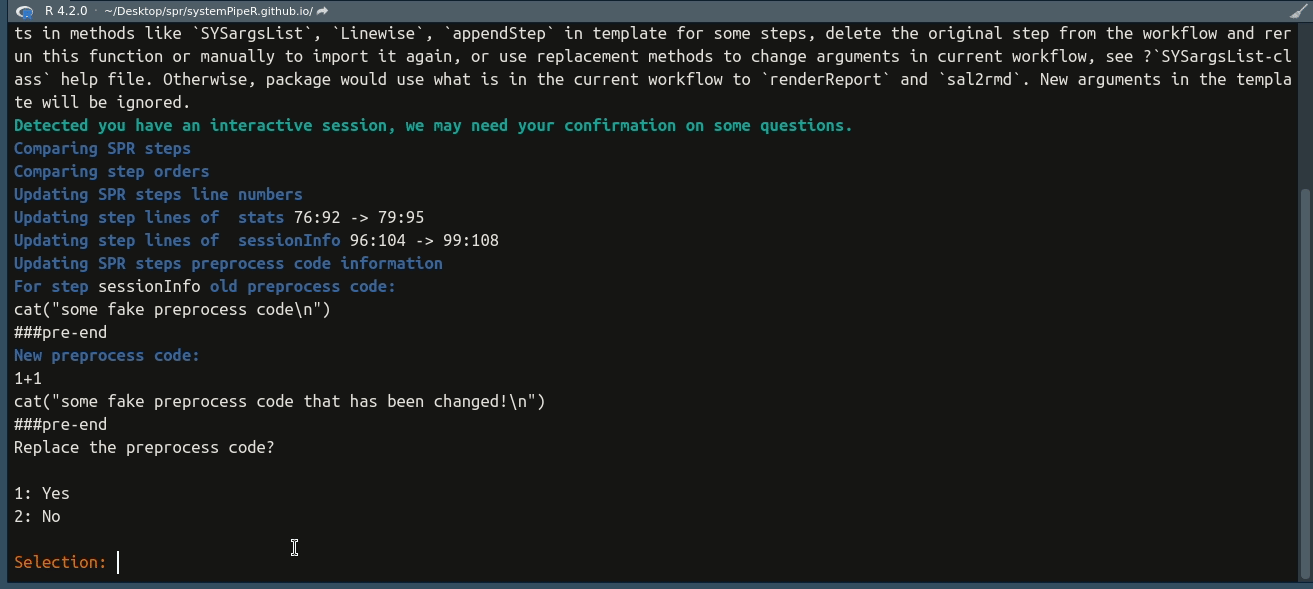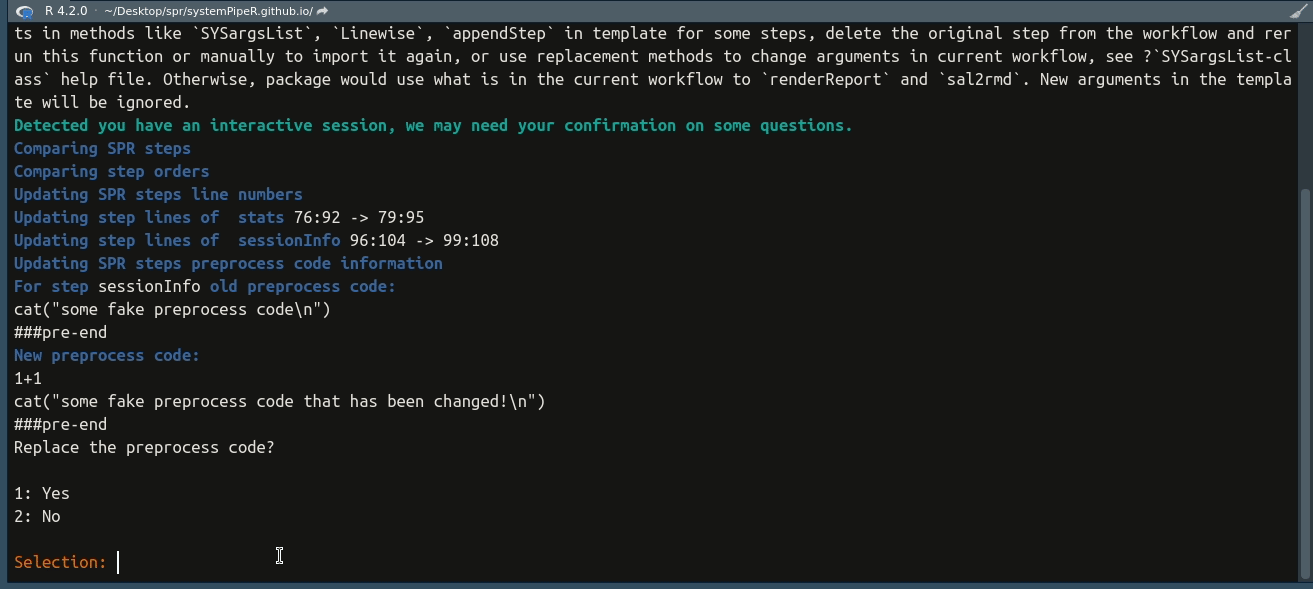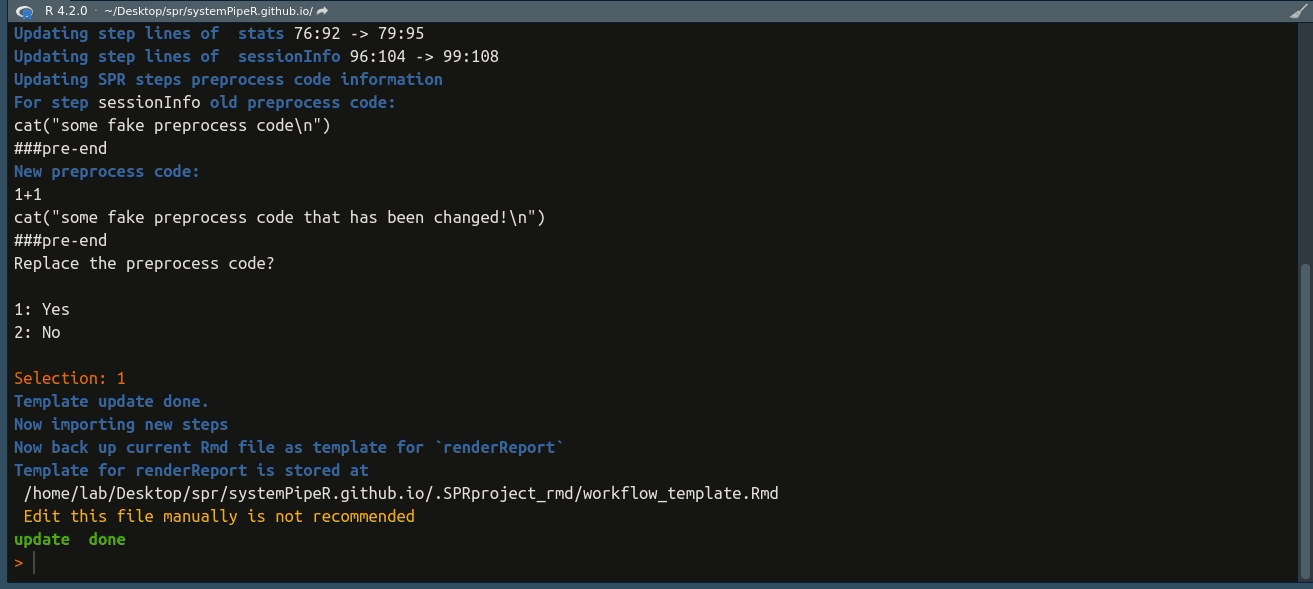
## Template update done.
## Now importing new steps
## Now back up current Rmd file as template for `renderReport`
## Template for renderReport is stored at
## /home/lab/Desktop/spr/systemPipeR.github.io/content/en/sp/spr/sp_run/.SPRproject_rmd/workflow_template.Rmd
## Edit this file manually is not recommended
## update done
Note for existing steps, and their preprocess code, they are not re-imported or re-evaluated.
Colors
Rendering the web document is not interactive, so colors are also removed. It is only gray color in code chunks above, but in the actual interactive mode, multiple colors are used to indicate the status as you have seen in the gifs.
Advanced templates
There are quite a few pre-configed templates that is provided by the systemPipeRdata package. You can also take a look at them individual here
Session
sessionInfo()
## R version 4.2.0 (2022-04-22)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Ubuntu 20.04.4 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.9.0
## LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.9.0
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
##
## attached base packages:
## [1] stats4 stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] systemPipeR_2.3.4 ShortRead_1.54.0
## [3] GenomicAlignments_1.32.0 SummarizedExperiment_1.26.1
## [5] Biobase_2.56.0 MatrixGenerics_1.8.0
## [7] matrixStats_0.62.0 BiocParallel_1.30.2
## [9] Rsamtools_2.12.0 Biostrings_2.64.0
## [11] XVector_0.36.0 GenomicRanges_1.48.0
## [13] GenomeInfoDb_1.32.2 IRanges_2.30.0
## [15] S4Vectors_0.34.0 BiocGenerics_0.42.0
##
## loaded via a namespace (and not attached):
## [1] lattice_0.20-45 png_0.1-7 assertthat_0.2.1
## [4] digest_0.6.29 utf8_1.2.2 R6_2.5.1
## [7] evaluate_0.15 ggplot2_3.3.6 blogdown_1.10
## [10] pillar_1.7.0 zlibbioc_1.42.0 rlang_1.0.2
## [13] rstudioapi_0.13 jquerylib_0.1.4 Matrix_1.4-1
## [16] rmarkdown_2.14 stringr_1.4.0 htmlwidgets_1.5.4
## [19] RCurl_1.98-1.6 munsell_0.5.0 DelayedArray_0.22.0
## [22] compiler_4.2.0 xfun_0.31 pkgconfig_2.0.3
## [25] htmltools_0.5.2 tidyselect_1.1.2 tibble_3.1.7
## [28] GenomeInfoDbData_1.2.8 bookdown_0.26 fansi_1.0.3
## [31] dplyr_1.0.9 crayon_1.5.1 bitops_1.0-7
## [34] grid_4.2.0 DBI_1.1.2 jsonlite_1.8.0
## [37] gtable_0.3.0 lifecycle_1.0.1 magrittr_2.0.3
## [40] scales_1.2.0 cli_3.3.0 stringi_1.7.6
## [43] hwriter_1.3.2.1 latticeExtra_0.6-29 bslib_0.3.1
## [46] generics_0.1.2 ellipsis_0.3.2 vctrs_0.4.1
## [49] RColorBrewer_1.1-3 tools_4.2.0 glue_1.6.2
## [52] purrr_0.3.4 jpeg_0.1-9 parallel_4.2.0
## [55] fastmap_1.1.0 yaml_2.3.5 colorspace_2.0-3
## [58] knitr_1.39 sass_0.4.1